Boosting AI effectiveness: the role of data prep in business

Imagine analyzing lots of data using AI. Let’s say, it’s a heap of comments from your customers, which you have no time to read yourself and need a little help processing. And then imagine that only 93% of them are processed, while 7% are left behind. Would you want to get to 100%? We’re sure you would.
And that’s basically what we did. Working on our project, Trevise—a tool designed to analyze customer feedback, our Research and Development team was trying to compare OpenAI with Google AI and how both of them process data. And while processing the data with those titans, we found that the key to their success isn’t just fancy tech—it’s all about getting the data ready.

After some smart data preparation, we saw a jump from handling 93% of comments to nailing it at 100%. And that’s a game-changer, right? Especially for businesses. So, we decided to spill the beans on why data prep matters so much in the AI game.
The significance of data quality in AI
The story goes like this: as we started processing data with Google AI and OpenAI, our exploration encountered a common hurdle: the challenge of effective content filtering. Google AI and OpenAI employ distinct strategies for content moderation. Google AI relies on “policy prompting,” utilizing a diverse dataset that encompasses both policy-violating and policy-compliant text and code. On the other hand, OpenAI develops content moderation models, including one based on the versatile Transformer architecture, trained on extensive datasets of text and code.
To address the limitations posed by content filtering challenges and to ensure a thorough analysis of all available data, we turned to data preparation. Recognizing it as a strategic solution, we implemented data preparation techniques as a prelude to subjecting comments to AI analysis. Data preparation emerged as the critical bridge between raw data and effective AI analysis. By refining and structuring the data before feeding it into AI algorithms, we experienced a transformative improvement in accuracy and efficiency.
So, how data quality affects AI data processing?
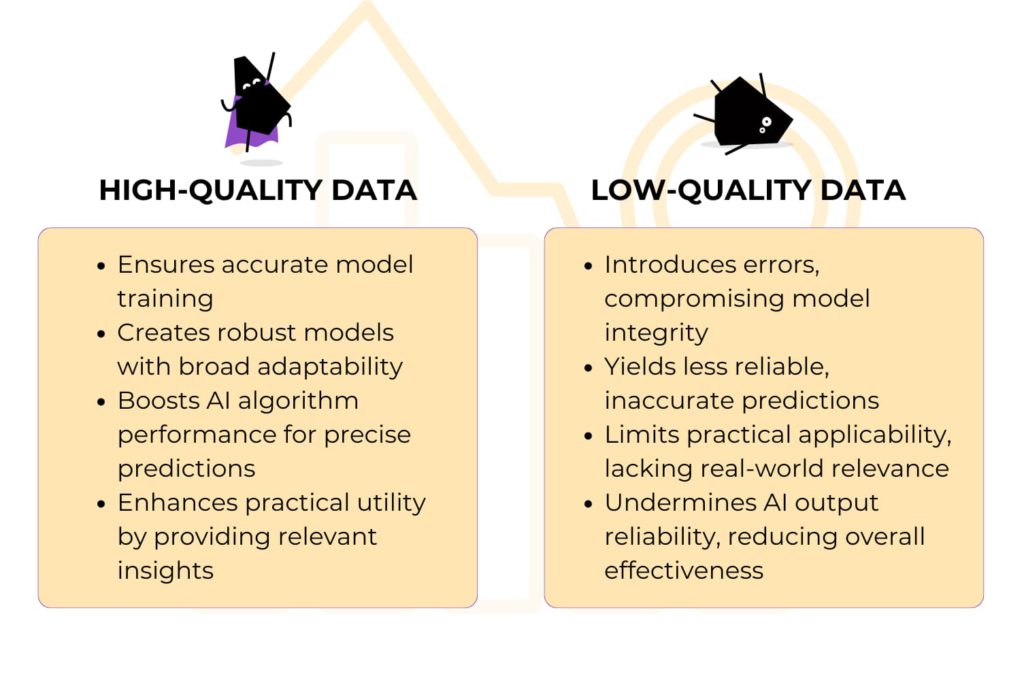
High-quality data is foundational for meaningful insights, accurate analyses, and confident decision-making. Organizations invest in maintaining and enhancing data quality to derive maximum value from their data assets. This commitment to data quality is particularly crucial in the context of leveraging advanced technologies like artificial intelligence and machine learning, where the reliability of the underlying data directly impacts the performance and outcomes of these systems. So, how exactly high data quality helps AI process the data?
- High-quality data facilitates accurate and effective training of AI models and helps in creating robust models that generalize well to new, unseen data, while low-quality data may lead to models learning from inaccuracies or noise in the data and results in less reliable and less accurate models.
- High-quality data enhances the performance of AI algorithms, leading to more accurate predictions and classifications, while low-quality data may result in unreliable and suboptimal predictions.
- High-quality data enables AI models to generate insights that are more applicable to real-world scenarios and enhances the practical utility of AI-driven solutions, while low-quality data may lead to AI outputs that lack relevance or fail to capture real-world complexities and limits the applicability of AI models in practical settings.
Optimizing data quality through data preparation
As we already understood, harnessing the full potential of AI tools relies not only on sophisticated algorithms but, crucially, on the integrity of the data that fuels them. This is where strategic data preparation enters the stage, ensuring that the data ingested by AI models is not merely processed but is of the highest quality. Let’s explore how different data preparation techniques unfold in the context of preparing data for AI tools.
Filling in the blanks: imputation
When data has missing values, the AI can basically miss the point and provide you with incorrect analysis. To fill in the gaps we use imputation techniques. When certain data points are not available or are incomplete, imputation involves estimating or filling in these missing values using various methods. For instance, in our research on AI analysing comments for e-commerce shops, we encountered incomplete data changing every “it” or “this” in a comment with an actual name of the product. Thus, imputation during data preparation ensured our AI models had a complete set for analysis.
Talking the same language: standardization
AI models work better when the data they process is consistent. Standardization ensures that diverse data formats and units are unified. For instance, in AI analysis of feedback, standardization ensures that diverse measurements, like word count, sentiment scores, and term frequency, are comparable by transforming them to a common scale. This process allows the AI to understand and compare these different aspects effectively, facilitating a more comprehensive analysis of the varied feedback data.
Cleaning up: duplicate removal
Duplicates in data are like unnecessary clutter confusing AI models. For instance, if you, as in our research, observe repeated comments, you need to prepare data removing duplicates. It, in turn, will streamline the data and prevent confusion in AI-driven analysis.
Making data useful: transformation
Transformation in data preparation is a technique that reshapes and adjusts the data to make it more suitable for analysis or modeling. This process often involves converting variables, creating new features, or modifying the data structure to enhance its relevance and usefulness.
Handling the tricky parts: categorical variables and grouping
AI often struggles with categorical variables. In our research, some comments referred to similar things differently. Data preparation grouped these variations, making it easier for AI models to comprehend and analyze the collective information.
Playing by the rules: legal and ethical compliance
Even in the realm of AI, compliance is crucial. Data preparation ensures our practices align with legal and ethical standards. For instance, when dealing with sensitive topics in comments, data preparation incorporates measures to uphold privacy rules.
Data preparation tools
Having explored the vital role of data preparation in our AI journey, we now turn our attention to the practical tools shaping your data landscape. Think of these tools as your business allies—they tidy up your data, structure it efficiently, and ensure nothing crucial is missing. Thus, they play a pivotal role in preparing your business information for strategic decision-making.

Data cleaning tools
Data cleaning tools, such as OpenRefine and Trifacta, using different data cleaning techniques, meticulously scan datasets, address missing values, correct errors, and enhance data reliability for accurate analysis.
Data transformation tools
Tools like Alteryx and Paxata transform data variables, standardizing scales, encoding categorical values, and creating new features. This ensures a uniform dataset ready for in-depth analysis.
Data integration tools
Data integration tools, exemplified by Talend and Apache Nifi, orchestrate the seamless merging of data from various platforms. This creates a comprehensive dataset, fostering a holistic view of business information.
Data profiling tools
Tools like IBM DataStage and Microsoft SQL Server Data Tools (SSDT) provide insights into data characteristics. They reveal patterns, distributions, and potential anomalies, offering a deeper understanding of the dataset.
Data wrangling tools
Data wrangling tools, including DataWrangler by Trifacta and Wrangler (Google Cloud), empower users to interactively explore and refine raw data. They facilitate the shaping of data for optimal analysis.
Data imputation tools
Tools like MICE (Multiple Imputation by Chained Equations) and FancyImpute are essential for completing datasets by imputing missing values. They ensure a comprehensive dataset ready for analysis.
Data governance tools
Data governance tools such as Collibra and Informatica Axon play a crucial role in upholding data policies and standards. They ensure data integrity, privacy, and compliance with regulatory requirements.
Data versioning tools
Data versioning tools like DVC (Data Version Control) and Delta Lake meticulously document changes, preserving the history and evolution of datasets. This ensures transparency and accountability in data-related decisions.
Automating data preparation in 16 steps
Automating data preparation is a pivotal step in ensuring that your AI models are fed with clean, relevant, and well-structured data. And this section outlines a step-by-step plan for companies aiming to automate data preparation before using AI for their data analytics.
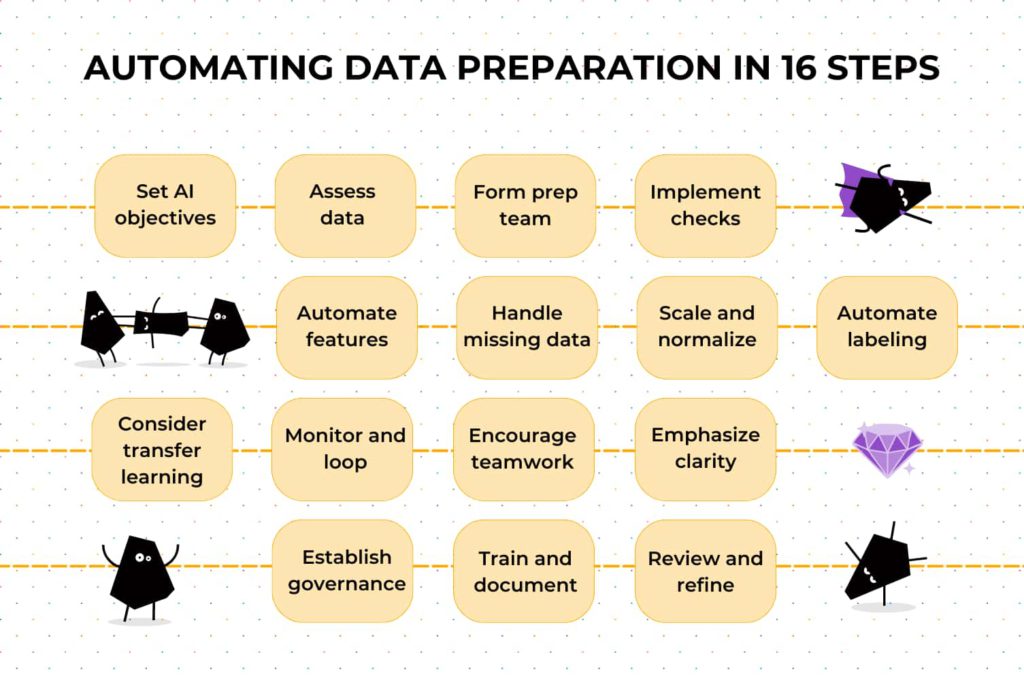
Step 1: Establish clear AI objectives
Define and document the specific objectives of your AI initiatives. Clearly articulate the tasks and goals your AI models are expected to achieve.
Step 2: Assess current data landscape
Conduct a thorough assessment of your current data landscape, leveraging AI data quality checks and data cleaning tools.
Step 3: Form a data preparation team
Collaborate with data analytics specialists with the expertise in data preparation, including AI data labeling, data cleaning, and machine learning data preprocessing.
Step 4: Implement data quality checks
Develop and implement automated data quality checks. These checks should identify and address issues such as missing values, outliers, and inconsistencies in the datasets.
Step 5: Automate feature engineering
Integrate automated feature engineering tools into your data preparation workflow. Tools like Featuretools or DataRobot can assist in transforming raw data into features suitable for AI models.
Step 6: Handle missing data
Implement strategies for handling missing data, employing AI-driven imputation techniques and algorithms.
Step 7: Scale and Normalize Data
Automate the process of scaling and normalizing data, ensuring it’s consistent across different variables. Seek tools that simplify this step and maintain data uniformity for better AI model performance.
Step 8: Automate data labeling
If your AI models involve supervised learning, automate data labeling processes. Utilize tools such as Labelbox or Snorkel to streamline the labeling of large datasets.
Step 9: Consider transfer learning
Explore transfer learning techniques, especially when labeled data is limited. For instance, fine-tune pre-trained models from TensorFlow Hub, optimizing them for specific tasks relevant to your AI objectives.
Step 10: Continuous monitoring and feedback loops
Establish continuous monitoring mechanisms for both data quality and model performance. Implement feedback loops that automatically update models based on new data patterns.
Step 11: Foster collaborative development
Foster collaboration between your data scientists and domain experts. Create shared workspaces using platforms like Databricks or Google Colab to facilitate collaborative model development and data preparation.
Step 12: Prioritize interpretability and transparency
Understand the importance of interpretable AI results. Look for tools that provide clear explanations of AI predictions, ensuring transparency and facilitating better business decision-making.
Step 13: Implement data governance and compliance
Integrate tools like Collibra for comprehensive data governance, ensuring AI data quality and compliance with regulations.
Step 14: Training and documentation
Provide comprehensive training on AI-driven data preparation processes and document the entire workflow for future reference.
Step 15: Regular review and optimization
Establish a regular review process for the automated data preparation workflow, continuously optimizing based on AI-driven insights.
And that’s it
In conclusion, the journey through data preparation for maximizing AI effectiveness unveils a critical aspect in the realm of information analysis. As we’ve explored the significance of data quality, delved into the intricacies of content filtering challenges, and outlined strategies for robust preparation, it’s evident that meticulous data handling is the key to unlocking the true potential of AI. Whether you’re navigating the complexities of OpenAI, Google AI, or any AI project, the message is clear: data preparation is the linchpin.
At GreenM, we understand the challenges of this transformative process. So, If you find yourself in need of expert guidance or assistance in steering through the nuances of data preparation, don’t hesitate to reach out. Our team is here to ensure that your data is not just prepared but primed for the extraordinary possibilities that AI brings to your business. Together, we can embark on a data-driven future where every bit of information is a catalyst for success.





