How to build Serverless .NET Core API with AWS and Vertica

Overview
Data storage is the most important part of any big data analytics solution. How you transform, store and access your data is the most important decision you’ll make when building such systems. These choices require compromises, but with a smart approach, we can build APIs to allow access to any type of data storage.
Let’s imagine you’ve created a platform that’s been working well for several years. But new technologies are released every minute, and someday you’ll want to renew your architecture to apply all these modern improvements.
In our case, we have a Vertica distributed analytical database. It’s hosted on AWS cloud along with the other components of our platform. We have a customer facing business analytics portal, which uses an API to get data from Vertica. The API service was built with ASP.NET WebAPI technology and hosted on an EC2 instance.

Our goal was to make our API highly available (HA) and scalable, so we decided to go with a Serverless approach. But at the same time, we wanted to keep refactoring scope small. Our ideal case was to just move the existing .NET source code to newer technology.
Options
AWS proposes several options for Serverless APIs creation and hosting
- AWS Lambda Functions
- AWS Fargate
Both these technologies have their pros and cons, which we’ll discuss in more detail in another article. In our case, the main factor was to use .NET Core technology in order to simplify migration from ASP.NET Web API. During investigation, we found out that the Vertica.Data package is not currently supported by .NET Core.
One option is to use the old but reliable Vertica ODBC driver in our API’s execution environment — but in Lambda, we don’t have a way to adjust the environment to use it. However, this is one of the main Docker advantages — you can build your own image with any libraries you want. So, Docker on top of AWS Fargate was our selected option.
Solution
To start with AWS Fargate, first prepare a Docker image with your application. Then, specify it in Fargate’s service and task configurations, along with other parameters like CPU, Memory and auto-scaling settings. You end up with an HA application running in Docker within its own auto-scaling group. On top of it sits a load balancer, which receives all incoming requests and forwards them to multiple Fargate tasks.

Today it is pretty easy to create a .NET Core API application running in the Docker. Just a few simple steps are needed.
- Create a new .NET Core Web Application project using Visual Studio and select the API type. Choose the latest .NET Core version and enable Docker support.
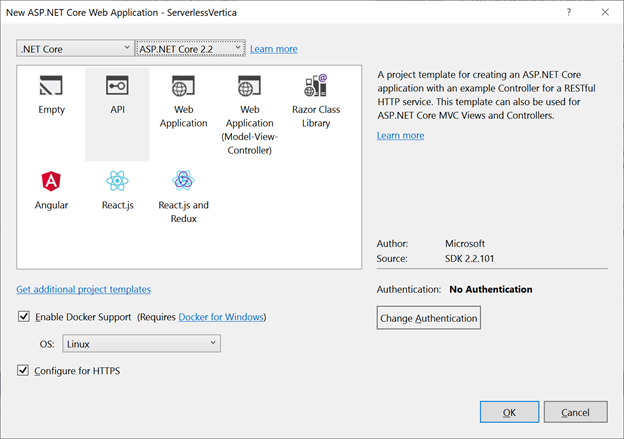
2. In the created project extend Dockerfile with Vertica ODBC driver installation and configuration.
FROM microsoft/dotnet:2.2-aspnetcore-runtime AS base
RUN apt-get update
RUN apt-get -y install curl g++ make bzip2
RUN curl http://www.unixodbc.org/unixODBC-2.3.7.tar.gz | tar xz
WORKDIR unixODBC-2.3.7
RUN ./configure && make && make install
RUN echo "/usr/local/lib" >> /etc/ld.so.conf.d/x86_64-linux-gnu.conf
RUN ldconfig
WORKDIR /usr/local/lib
RUN mkdir -p /var/log/unixodbc
RUN mkdir -p /opt/vertica-odbc-driver
RUN cd /opt/vertica-odbc-driver && curl https://www.vertica.com/client_drivers/9.2.x/9.2.0-0/vertica-client-9.2.0-0.x86_64.tar.gz | tar xz
RUN cp /opt/vertica-odbc-driver/opt/vertica/include/* /usr/include
RUN echo "[VMart]" >> /usr/local/etc/odbc.ini
RUN echo "Description = Vertica Database using ODBC Driver" >> /usr/local/etc/odbc.ini
RUN echo "Driver = VerticaDSN" >> /usr/local/etc/odbc.ini
RUN echo "[Vertica]" >> /usr/local/etc/odbcinst.ini
RUN echo "Description = Vertica Database using ODBC Driver" >> /usr/local/etc/odbcinst.ini
RUN echo "Driver =/opt/vertica-odbc-driver/opt/vertica/lib64/libverticaodbc.so" >> /usr/local/etc/odbcinst.ini
RUN echo "Locale = en_US" >> /usr/local/etc/odbcinst.ini
RUN echo "[ODBC]" >> /usr/local/etc/odbcinst.ini
RUN echo "Threading = 1" >> /usr/local/etc/odbcinst.ini
RUN echo "[Driver]DriverManagerEncoding = UTF-16" >> /etc/vertica.ini
RUN echo "ODBCInstLib = /usr/local/lib/libodbcinst.so" >> /etc/vertica.ini
RUN echo "ErrorMessagesPath = /opt/vertica/lib64" >> /etc/vertica.ini
RUN echo "LogLevel = 4" >> /etc/vertica.ini
RUN echo "LogPath = /tmp" >> /etc/vertica.ini
ENV ODBCINI=/usr/local/etc/odbc.ini
ENV VERTICAINI=/etc/vertica.ini
3. Add the System.Data.Odbc NuGet package to the project and start working with the Vertica database. Please note that some SQL queries should be adjusted to ODBC style, using the question mark ‘?’ instead of named parameters.
That’s it, only three steps! A source code example of these APIs can be found on GitHub:
https://github.com/illiasaveliev/serverlessvertica
Conclusion
Using this approach, we can build .NET Core APIs for any kind of data storage. Make them serverless via the power of AWS Fargate, or just run in a simple Docker process or scale using Kubernetes.
Thanks for reading — hopefully this case is useful. #everythingwillbebigdata
WANT TO KNOW HOW TO BUILD AWS SAAS PLATFORM FROM SCRATCH?
See how to improve and adapt technologies in order to scale the system from 0 to 10K users during a rapid customer growth with the possibility of a quick onboarding.





