A Quick Way to Refine Raw Data Into Dollars

Imagine a Company where software is not their primary business, but rather a necessity to support and tie together communication devices, such as wireless voice-activated badges and smartphones.
Software binds these devices into a powerful network, enabling a wide range of use cases. This includes calling into a group with first-to-answer policy, or a calling to a job role instead of a specific person, such that employees currently on duty can be reached, or broadcast voice messages.
The Company deploys this System on the customer’s premises on the local network. The system generates a massive amount of logs that can be delivered to the Company data center for further analysis in the event of any issues.
Logs are delivered as Zip packages to the Company FTP server. The ZIP package contains various log files, including log files for multiple system-related services, operational system logs, database dump, and system configurations. While having a weak structure, and no single format even for system-related components, system logs still contain useful data.
For example, they provide communication patterns between customer employees, level of system utilization, device battery levels, and how frequently they require re-charges, and much more. Additionally, the Company stores backups of logs, further enabling retrospective analysis.
What options does the Company need to have to unleash the power of logs?
Implement structured logging and build analysis on top
First of all, instrumenting code with structured logging is the right way to go. Having logs in a single format with at least partially common schemas such as JSON or CSV enables a wide range of software such as ELK stack and Splunk to do the first-level analysis and provide simple insights.

However, let’s take a closer look at this approach. In our case, the Company already owns and supports the existing System. There are plans to deliver new features to end-users, to support new modern device models and to extend the System with faster communication protocols.
At the same time, it would require dedicating some precious time from the Team actually developing the System to outfit the existing code with proper logging. What features should be excluded from the scope then? Should the Company extend the schedule and change the delivery date?
But, even in the case of resources for log instrumentation being found, what would the Company get? Structured logs are not the end product; tools on the market are not cheap and require a broad set of skills to make sense of logs data.
Additionally, to enable structured logging for a specific customer, the Company has to install this latest version on the customer premises, which limits the possibilities for good customer coverage. The opportunity to do retroactive analysis on backups is lost as well.
Collect existing logs and build analytics on top
What if the Company takes another approach and tries to make sense of existing logs? Well, this approach takes the pressure off the primary product team as no changes to the System are required, and a dedicated team can develop it.
No updates to the systems on customer premises are currently required as well, and we keep the opportunity to do retroactive analysis.
This option is great to keep fast time-to-market and also gracefully migrate to better logging in the primary System to support even more insights.
Let’s review what it takes to follow this path.
Log-based analytics with weakly structured logs
Log analysis and pattern discovery
So, we have a massive amount of ZIP packages containing various log files. How do we discover useful patterns in them? How do we identify the meaning of each pattern?
Anexcellent way to start with a massive task, is to take a bite out of it; in other words, we can narrow the scope. This is not a set of random log files, and we know the system they belong to, and we know it does communication.
So let us pick some useful event that is present in the log files and try to identify a potential set of patterns covering it. For example, we can take a call from one device to another.

Another way to narrow the scope is to choose a specific version of the system to work with and a particular component of the system. Moreover, we can start with one particular set of log packages big enough to cover a variety of cases we need, but small enough to be parsed on one machine using a console app quickly.
The system source code can be complementary to the log files. We can decide to start with identifying the code paths leading to the call event and finding lines of code with logging. Another way to identify patterns, is to use the system and monitor what log lines it generates during specific use cases.
In parallel with log discovery, the team can build a log parsing POC implementing found log patterns. At this stage, a pluggable approach can be utilized to quickly extend a POC with newly found patterns.
Data analysis challenges
Now that we have identified a basic set of patterns, we can start extracting events out of them, and combine these events to build facts and insights.
Extract events
Itis quite trivial to generate events where an event is one to one with a logline. However, it might be challenging to build events based on multi-line patterns, as it is not a rare case when services work in a multi-threaded mode. For logging, this means that log lines from other threads can be mixed into the multi-line pattern you are seeking.
We can solve this challenge using the following logic:
- If log patterns belong to some entity with identity such as an id or a name available as a part of the logline, we can split log lines into groups by this identity and then apply event extraction logic. In the case of our communication system, a device id might be a part of the logline. Sometimes, if we are lucky, the thread id might be a part of the log as well.
- If case logs can’t be split into groups related to a particular entity, it might be a good idea to build a stateful log parser. By stateful, I mean that a log parser memorizes incomplete patterns (for example where just first line of the pattern is found, but not the finishing one) and keeps seeking until the pattern is complete. This approach might be especially useful if a pattern’s meaning depends on previously registered events. In this case, not only incomplete events should be kept as a part of the state, but also the last event, or a series of latest events.
As a result of event extraction, we get a set of events like “call initiated,” “call started,” “call finished,” “call failed,“ and so on. And most likely, with structured logging you would quickly get this set of events, but not more. Can we build some analysis on top of this data? Yes, we can. However, it might be too low level and won’t bring useful insights all at once.
Advanced analysis
Tobuild a deeper insight, we have to combine these low-level events into facts. For example, we can combine “call initiated,” “call started,” and “call finished” events into the fact “Call” with attributes like call initiated time, call picked up time, call finished time, caller device, and callee device.
This information is much more useful for the analyst as it opens up a higher space for higher-level analysis. We can identify a period with a pick load, or identify communication patterns and critical paths related to a specific business operation on the customer side.
Utilities
There are other challenges not directly related to the analysis, but profoundly impacting its quality. One of those is log quality. As you remember, the Company collects logs on it’s FTP server. So there is no guarantee that the log package is not broken, or has not been sent twice.
Additionally, some of the log files inside the package might be still running log files, and they will be present in the next package as well. In order to ensure the best possible quality of logs coming for analysis, we have to build a log registry containing not only the package itself but also information about its content such as file name, file size, timestamp and so on.
The log processing component can then use this registry to update the status of processed files and exclude already processed files.

As mentioned in the beginning, the Company deploys the system on customer premises, which means that at any particular moment in time, there are multiple different versions which have to be supported.
For the analytics system, this means that we have to support different versions of patterns for the same event or even the absence of specific events. This challenge can be resolved using the pluggable approach. We can implement each pattern, fact, and insight as plugins with the system versions they belong to as a part of their metadata.
Now we can identify the system version at the beginning of processing, or even as a part of the log registry and use only compatible plugins.
The Pluggable approach is also key to further system logging improvements. Now the primary team can steadily improve logging inside the system, and on the analytics system side, new plugins can be added to support the new version.
Technical solution
Let’s see how the solution described above can look like if hosted in the Company data center.
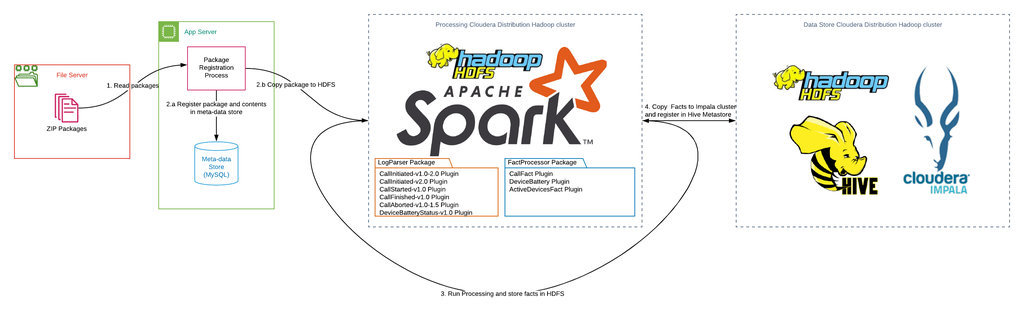
On a high-level solution, it consists of 4 major steps:
1. The Package Registration process copies a ZIP package from File Server to the Application Server.
2. The Package Registration process validates the ZIP package integrity, reads its contents and registers the ZIP package, its validity status and contents info into Meta-data storage. If a package is valid, it is copied to the HDFS of the Processing cluster.
3. The Spark job on the Processing cluster consists of 2 stages:
a. ZIP package and its contents are read, and Events are extracted by the LogParser package and a corresponding set of plugins.
b. FacctProcessor transforms and combines Events into facts and insights, and stores the result in a local HDFS.
4. Facts are copied from the Processing cluster to the Data Store cluster and are registered in Hive Metastore. Next, Facts become available for querying by Cloudera Impala.
Summary
With the approach described above, you can get to market with a log-based BI solution as quickly as possible. This means that the product team, sales, and management can gather valuable facts and insights about the System usage patterns and potential for further upselling or about clients at risk.
The primary team keeps its focus on the System and end-user features delivery and gains time to plan and implement structured logging inside the System properly.
Would you like to discuss this case further? Let us know how GreenM can help you — our high-level dev team would be more than pleased to schedule a free online meeting to devise the best solution with you.
WANT TO KNOW HOW TO DESIGN A HEALTHCARE DATA PLATFORM?
Learn about our approach to building an agile ecosystems with an architecture of multiple secure data layers, distributed storage and internal and external APIs.





