Top 4 AWS Patterns of Highly Available API

We want to tell you about a few common patterns that can be used to build highly available APIs on top of AWS infrastructure. We will highlight each of them and briefly describe the pros and cons.
Overview
You could easily ask the question, why should an API be highly available? In our world of big data and unpredictable users load, you should guarantee the responsiveness of your application. It is the minimum necessity to save the business money and not lose your clients. Such important architectural characteristics like high availability and scalability can help you with this. You have to always keep them in mind while creating new modern applications. And as you know, today, the API is one of the main parts of any system.
High Availability in your application
Let’s start off with a brief explanation of high availability and the main challenges of achieving it.
High availability (HA) is a characteristic of a system, which aims to ensure an agreed level of operational performance, usually uptime, for a higher than normal period.
As you might understand, availability usually measures in “nines” like 99.999% “five nines”, that means a percentage of uptime in a given year. In other words, only 5 minutes and 15.6 seconds, your system can be in a downtime state during the whole year. So the question is — how to reduce the downtime?
The usual answer is to add additional components, which will provide the service while the main components will be broken (in downtime). The idea is to eliminate the single point of failure by adding redundancy to your application.
The typical application implementation has three main parts Client(1), API(2), and Data Store(3). Therefore, if you want to make your application highly available, you must guarantee availability for each of the 1, 2, 3 parts. Moreover, if you’re going to create an unbeatable system, you have to follow the AWS best practices for fault-tolerant systems. Say, use multiple availability zones or even regions, together with failover rules in the Route 53 service.
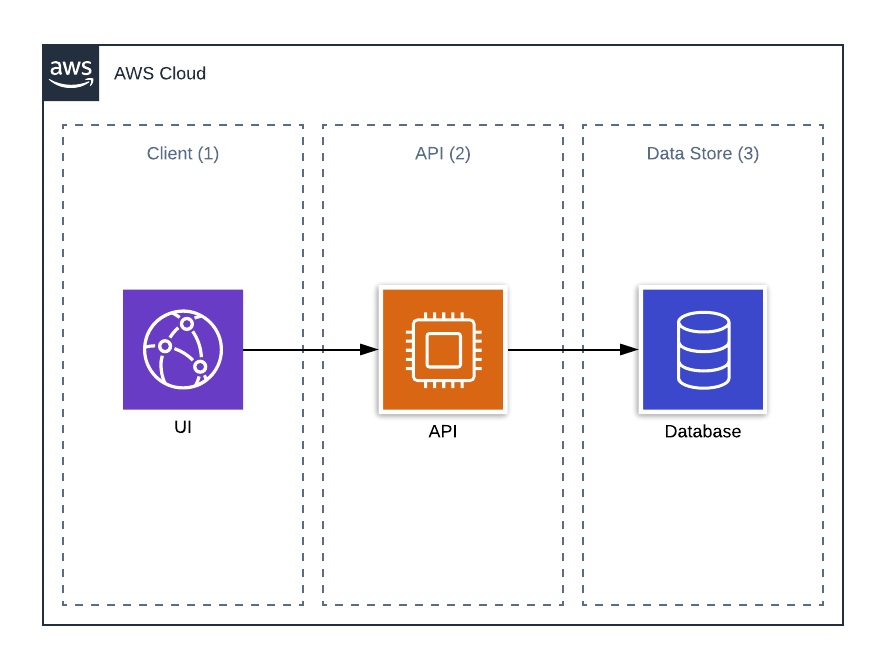
AWS helps you to resolve the availability challenge for each layer. It provides all the required HA services for this.
- Client (1) — for UI implementation, you often create a web app, which can be stored on Amazon S3 and served via Amazon CloudFront.
- Data Store (3) — AWS provides multiple options to persist data. You can choose between relational and NoSQL databases, like common Amazon RDS, or Serverless Amazon Aurora, or DynamoDB, etc.
- API (2) — here, AWS offers a broad set of tools for making API highly available. As you may have guessed, it will be the main focus of this article. We will describe the common deployment patterns of highly available API.
Just a few disclaimers before we start:
- We assume that services like AWS API Gateway or AWS ALB are fault-tolerant and highly available by themselves.
- We won’t show all possible API architectures, just the common ones.
Required preparations
Before making API highly available, it must support one important property — to be idempotent. By idempotent, we mean that each request must be independent, produce the same outcome, and not related to the previous one. So, when it is multiple API instances, then it doesn’t matter to which server request is redirected.
There are two standard techniques on how to achieve it:
- Use some long-time storage for user sessions, like shared-memory or databases. On AWS, it could be Elasticache or DynamoDB.
- Send all the required user information with each request using cookies or tokens.
The front door to your API
As an API developer, you always tackle a lot of challenges. And a lot of them come from the fact that usually, the API is public. Therefore, you have to protect the API, documents, monitors, etc.
AWS API Gateway comes to the rescue. It addresses all these problems and reduces the operational complexity of creating and maintaining your API. It has several important features like requests throttling, authorization, request and response transformation, import and export documentation, advanced logging and caching. We will use it in all API patterns below.
Classic EC2 way
The traditional pattern is to host your API on several EC2 instances and configure the application load balancer to redirect traffic between them. Moreover, to add scalability, you can set the Auto Scaling group to add or remove EC2 instances based on the current load.
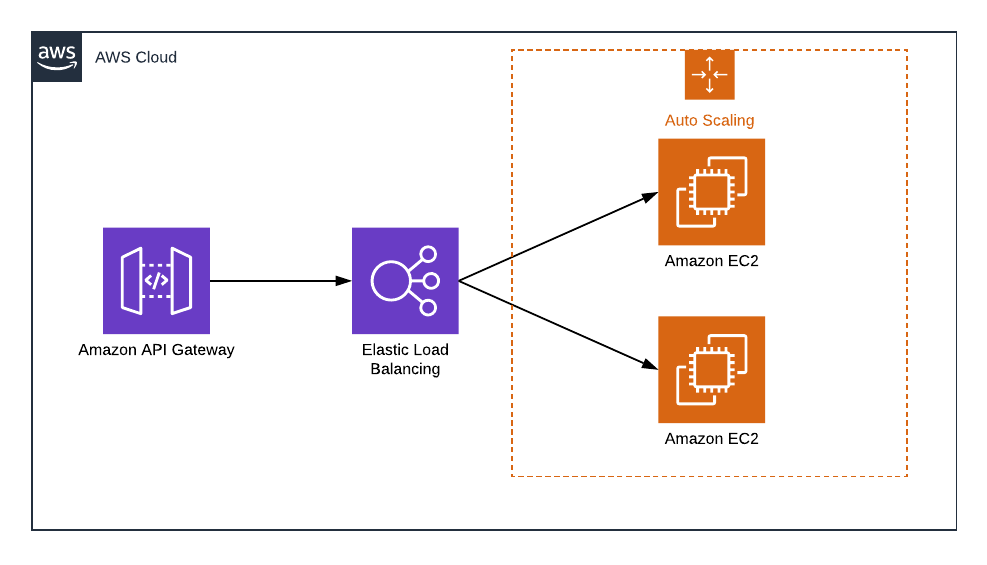
HA API — EC2
✔️Pros
- It is simple to setup such infrastructure
- It supports any API framework, like Java, .NET, Python, etc.
- Configurable — you can put on the EC2 whatever you want
- Almost no limits, you can increase storage, memory, CPU, etc.
❌Cons
- Infrastructure costs
- You are responsible for instance images management
Containerized API on top of AWS ECS
AWS provides Elastic Container Service, which allows you to run your API in the Docker environment.
The pattern is straightforward — you build your API inside the Docker image. Then ECS will manage everything else, host it, run and connect to other AWS services. ECS supports auto-scaling policies and rules, as well as built-in monitoring and metrics.
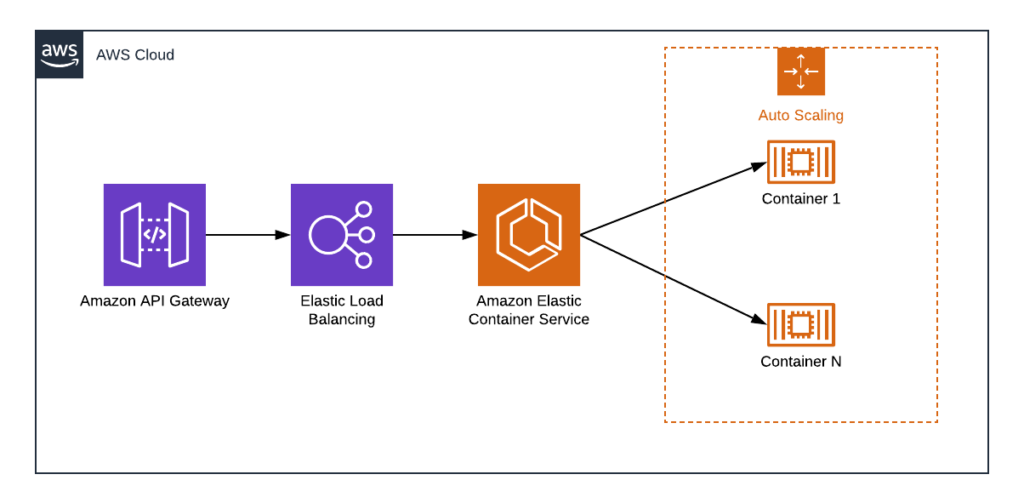
HA API — Containerized
ECS has different flavors:
- Amazon EC2 — runs Docker on top of EC2 worker nodes, can be On-Demand or even Spot instances.
- Amazon Fargate — also named serverless, as it decides where to run Docker containers, you just need to specify the desired network, memory, and CPU parameters.
- Amazon EKS (Elastic Kubernetes Service) — allows you to setup a Kubernetes cluster on AWS.
✔️Pros
- Easy to build and test API on your local Docker environment
- Configurable — you can use any available Docker image, or create your own with all required libraries
- Simple high availability and scalability settings
- Cheaper infrastructure costs in comparison to classic EC2 approach
- No server management overhead in case of AWS Fargate
❌Cons
- It still has some limits, for example, storage for AWS Fargate
- Infrastructure management, except AWS Fargate
- Docker images management and version updates
Elastic Beanstalk Application
AWS Elastic Beanstalk service allows you to create an application in only a few clicks. The steps for this pattern are pretty simple
- Develop an API code.
- Open AWS Console and create a new AWS Elastic Beanstalk application.
- Choose desired runtime, auto-scaling, and other configuration parameters.
- Run your application.
Please note, that you can use classic EC2 pattern or Docker with ECS service for application deployment.
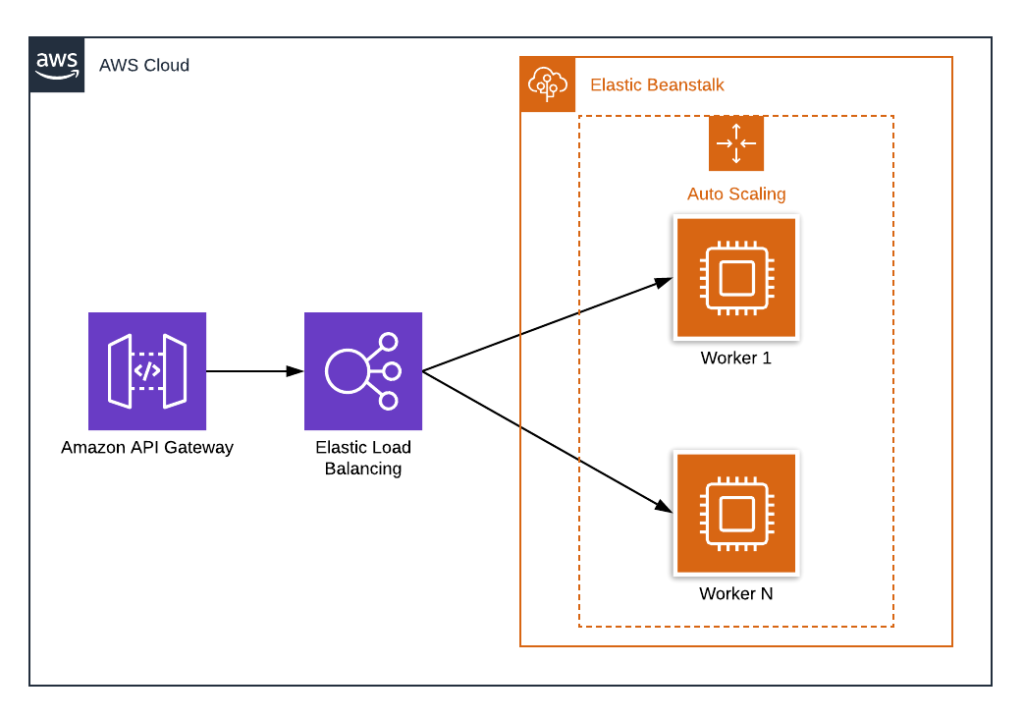
HA API — Elastic Beanstalk Application
✔️Pros
- Easy to learn and to start with AWS deployments
- Supports EC2 or Docker deployments
- Simple high availability and scalability settings
- No server management overhead
- No additional service costs
❌Cons
- Slow and not flexible deployments
- Application versions management
- Hard to fine-tune, control the whole application stack
- Not suitable for all API frameworks and libraries
Serverless AWS Lambda approach
Nowadays, it’s popular to build serverless applications. They eliminate the server management overhead and bring a lot of cool features by default, like high availability and scalability.
The pattern is to build your API as a Lambda functions and use API Gateway to trigger them for all incoming requests.
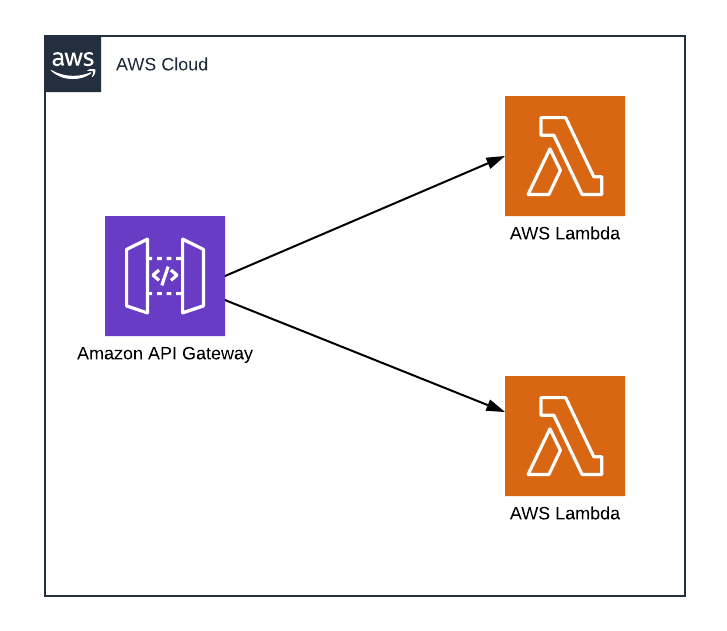
HA API — Serverless
✔️Pros
- Highly available and scalable by default
- Easy to build
- No infrastructure management
- Low infrastructure costs
❌Cons
- AWS Lambda has some limits, including configuration, timeout, memory, CPU, etc.
- Not suitable for all API frameworks and libraries
- Hard to monitor and troubleshoot in the event of complicated deployment schema
Conclusion
We hope the patterns above will help you to make the right decision for your future API infrastructure on top of AWS. That will guarantee high availability and scalability for your application. Of course, there are a lot of other factors and decisions, such as choosing the right database, storage, etc. However, at least you will be confident with the API level.
If you have any other questions about AWS infrastructure solutions, the GreenM team is happy to help. Drop us a line to learn more.
WANT TO KNOW HOW TO BUILD AWS SAAS PLATFORM FROM SCRATCH?
See how to improve and adapt technologies in order to scale the system from 0 to 10K users during a rapid customer growth with the possibility of a quick onboarding.





