Data Pipeline Installation Quality

You asked for it. We delivered! Here’s the testing story shared with the community on QA Data Monsters Meetup (#DQM) of how we verified a new version of Data Import upgraded in the Amazon cloud using its services.
The testing approaches and types discussed are universal and can be applied to any project to safeguard data update quality.
Grab your favorite beverage. Kick back. Enjoy. Write to us, should you have any comments and questions. We’ll be super glad to be of service!
Evolution Testing Task
A few words about our great client and partner. With the help of our services, one of the oldest USA Healthcare Research corporations does processing and analysis of patient feedback for American clinics, to see whether people are satisfied with medical services, to address any concerns, and thus increase patient loyalty.
The project is a web application with a set of dashboards and reports based on a relatively small Data Mart, containing data from 300 clinics that are fully refreshed daily by data imports from various operational data sources.
The story began when the data was growing rapidly and the sales forecast said it would skyrocket soon. By that time, we already struggled to fit the import into the timeframe from a moment when the new data was available to the expected site update at 8 a.m. In addition, we received new business requirements for synchronous updating of all application modules.
With this in mind, we decided to optimize the import process by transferring it to Amazon services, since the project has already “lived” in the cloud.
So, summarize. Project milestones:
🚩Daily Runs
🚩Full Refresh Mode
🚩300 Customers
🚩~ 500 Mln rec / tab
🚩~ 5h ETL time
But wait. How Did We Deal?
Some Tech Details
A Data import passes three well-known steps – Extract, Transformation and Load (ETL). On the scheme below you can see the project’s ETL.
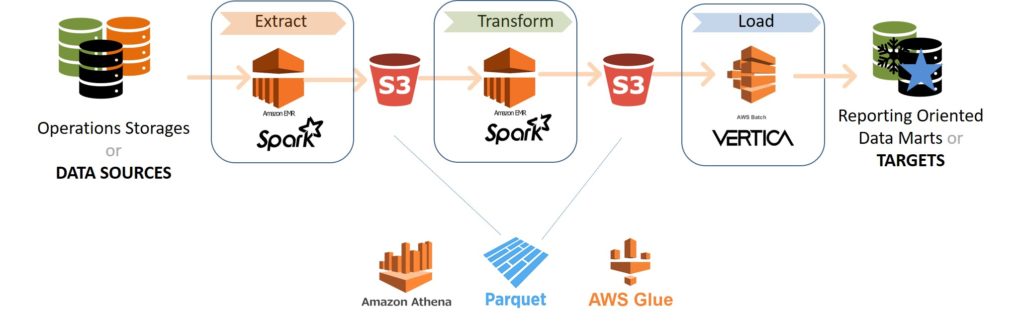
In the Amazon cloud, the new process was set up in a way that for extract and transformation we used temporary EMR clusters, and to upload results to data mart Batch service was used.
The results of each step were saved as files in the S3 catalog to be used on the following step. In this way, we collected data from different sources in one storage – Data Lake.
It allowed us to build the Pipeline with a flexible architecture, sequential and parallel steps, and introduce dependencies. The code and configuration of the Pipeline are also stored as files in S3.
Several Lambda services were set up to monitor the current state of the Pipeline and control the start of a desired stage. (You can check out more on that Pipeline architecture in some of our other posts, and stay tuned for the upcoming, cause the Pipeline got optimized with the new AWS features!)
Since the technology and architecture of the ETL process have changed, we needed to verify that the new Pipeline gives a result with the same data quality as then current production ETL version, and be sure that it works faster, and is more convenient and reliable to use.
Hold on. What do we have?
The data sources didn’t change; the business transformation rules, and the Data Mart schema remains the same. On the other hand, since the whole “filling” was replaced, an error can occur everywhere, so we need to check all the contents of all tables. However, if you do it by comparing data items in Data Mart against the source, it would take a long time.
That’s why we used ETL Regression Testing, a comparison of two Data Marts: a tested one – created through the new Pipeline and the Reference one- created through the previously thoroughly tested Production ETL version.
Regression via Reference Data Schema
We imported data into both Data Marts from the same set of sources and then compared these schemas through the table-by-table SQL queries.
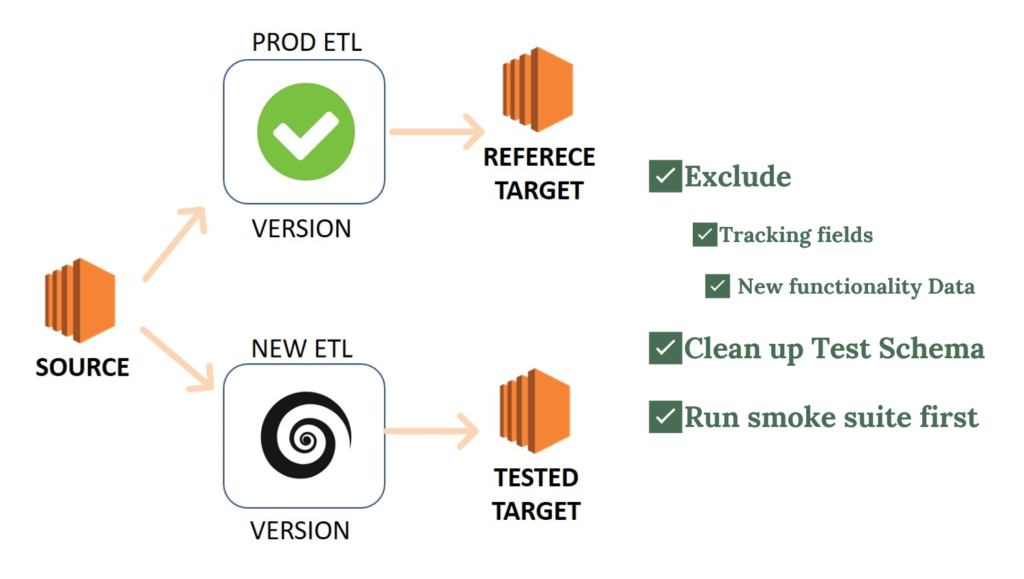
The essential points you should pay attention to include:
- Before each launch, the tested Data Mart needs to be entirely cleared.
- It’s necessary to exclude in advance any fields that may differ (log fields with the time of adding or modifying a record, or fields for new functionality).
- At first, you have to run the smoke test and check the tables for data and duplicates, next for the number of records, and only then can you compare the entire contents.
FitNesse For ETL Regression
We use Fitness Web server to automate ETL testing, where each test is an HTML page with an evident structure. You can use a readymade set of checks, the so-called fixtures, or write your own.
For Regression testing, the developers helped us with the creation of fixtures. And testers for each table created a config file with a table name, a unique record definition, and a list of fields that should be excluded from the comparison – as simple as that.
In a test, we indicate the following parameters: which engine for checks must be used, and where to connect, determine the test and reference Data Mart schemas and send just one parameter to the fixture – the config file of a table. After a test run, we get a precise result.
Regression Challenges
We faced three expected issues during the regression testing:
1) To test a change or fix we had to wait for a while, as ETL took a long time to run;
2) The tests hanged for large tables;
3) Data on the Test environment was incomplete. Since we work on a project where the data is protected by law, we didn’t have some parts of source data.
What Did We Do?
Manual Inspections
We didn’t wait until the Pipeline run is finished; we began to inspect its configuration and data processing requests code.
It was very convenient to do thanks to the chosen architecture – everything is very readable, structured, and stored as files in S3 that are easy to download.
Inspections help to identify errors at the earliest stages, even before the start of import. For example, some changes are made in many tables via copy-paste, or sometimes developers forget to apply them to others.
Partial Pipeline Run
Also, we can use the partial Pipeline run to save time because most errors occur at the transformation step. Therefore, we used the output of Extract step from the previous test, and run the pipeline, not from the very beginning. Additionally, we were able to disable synchronization so that different modules do not wait for each other every time.
Source Data Limitation
You can limit the amount of imported data by modifying the Pipeline configuration or by physically changing the data sources. Some Test Source Data could be physically deleted, but due to the dependencies, it’s quite a challenging thing to do. Instead, you can find a rule in business logic that filters data, for instance some flag, and change the value of this flag in the source database to limit the imported data volume.
Test Data Modeling
Also, to solve the issue of missing data, you need to carefully model it by analyzing the possible options. It’s better to do it by using a script that can be reused again.
Non-functional Pipeline Testing

So, we checked that the Pipeline is functioning as required, and provides the desired quality of data.
As for non-functional requirements, we collected statistics on the Pipeline run time during the regression, thereby confirming that its speed is sufficient. Next, a Performance check was conducted.
Also, during the inspections of the Pipeline code during Regression, we made sure the passwords for connecting to the databases are not stored in the configuration files, but rather set up in Amazon’s Secret Manager service, that access to s3 folders and Data Lake is limited – and those were Security checks.
Among other non-functional requirements, let’s take a closer look on Usability and Reliability. At the end of the day, those two define whether the Support Team, who will manage Pipeline in production, will fall in love with it or not.
All the rest of the non-functional types of testing are also important, but they require a long separate discussion. In particular, the topic of Pipeline Scalability was covered before (You are welcome to read our previous post Scalable Data Pipeline. Be Ready for Big Changes).
Usability Testing
To test the usability of ETL, you can partially apply the same heuristics as for app interfaces testing — user awareness of system status and errors, system flexibility, ease of use of various configurations, and the availability of clear documentation.
During the Regression testing, when we worked with the Pipeline settings, we ran through all expected usage scenarios, and it was easy for us to evaluate the usability and outline the further development tasks to facilitate some operations (for example, to introduce auto-restart for some stages of processing).
Reliability Testing
We conducted a Risk assessment – created a list of possible issues to check the reliability and simulated the failures to make sure that Pipeline stops working as expected, i.e., incomplete new data doesn’t get into production, data is not erased, etc.
Such experiments are very convenient to do in Amazon cloud using its services – the tester can make some data sources or Data Marts unavailable by turning off a hosting server instance, stop the cluster during data processing, specify a nonexistent table in configuration, create a pile of logs in the repository to imitate a rather long history of usage, etc.
However, there are some pitfalls to keep in mind while playing.
Reliability Testing Faults
1) At first, we did not pay enough attention to checking the Amazon service logs during the pipeline testing. In particular, we underestimated the severity of the exceptions generated a couple of times by service responsible for a pipeline step start. As a result, it led to some delays between different stages.
2) Secondly, we overestimated the reliability of AWS.
The scenario of a data processing failure due to a lack of Amazon resources was defined as one with very low probability. Thus, the development of functionality responsible for a Pipeline step auto-restart after alike error was not included in the scope of the initial version.
Unexpectedly, when the pipeline has been in production for quite a long time, we noticed the error telling that we don’t have enough resources. We wrote to Amazon support and received the answer that the problem is on their end and would be resolved, which they did – but we still got a production update delay.
3) Finally, during Volume testing, we saw that the Pipeline’s work slowed down because of a large number of files from previous launches – the monitoring function was affected. Still it was decided to automate old records archiving in the next Pipeline version, for now transferring this responsibility to the Production Support team as a manual-maintenance task.
The supporting documentation had relevant instructions, but with no emphasis in big red letters on WHEN exactly it should be done. As a result, the moment was missed, and – what an unfortunate coincidence – monitoring did not work on exactly that day when Amazon ran out of resources.
Lessons Learned
Based on our experience, we would recommend the following:
1) Look behind the scenes
As in UI testing, you need to check, not only at the actual results, but also make the absence of a logged Exceptions a part of the Acceptance Criteria.
The monitoring of the services should be constant, accompanying each test run. It’s not a one time event.
In our case, for development in the Amazon cloud, in addition to usage of ready-made services management and log monitoring tools, it would be ideal to set up up a CloudWatch Alarm that will automatically inform the team about a problem during development.
2) Do recovery training
Even if a risk is defined as low, you can not only mention it during acceptance demo, but also arrange a recovery “field training” with the Production Support team. Especially when it is easy as ABC – document, demonstrate and let them try it!
As otherwise, having no experience, even professionals will hesitate to interfere in the production processes, which means your team will be asked to do so while being distracted from other tasks. And time differences may make an insufficient recovery cost even higher.
3) The devil is in the detail
Make sure that Support tasks for a team that will take care of the Pipeline in Production are documented with all the details specified, accepted and relevant processes established with the proper framing.
“That’s it, we all done!” – we could have said. But that was not the end of the story…
In an ideal world move to another technology stack is an independent process that must not coincide with changes in functional requirements. In the real world, however, it is not the case – often migration to a new stack is done alone with new module development.
We will discuss it in more detail in our next article Data Warehouse Testing.
Thanks for reading! Stay awesome.
WANT TO KNOW HOW TO DESIGN A HEALTHCARE DATA PLATFORM?
Learn about our approach to building an agile ecosystems with an architecture of multiple secure data layers, distributed storage and internal and external APIs.





