Data Warehouse Testing

In the first part of the story shared with the community on QA Data Monsters Meetup (#DQM) we discussed how to check data pipeline work when data storage requirements remain the same, while technologies standing behind it evolve.
We covered ways to ensure the new Pipeline version produces the right data, works fast, is reliable, and easy to use.
It’s rare luck when you are given a chance to concentrate fully and solely on improvements. As you may know, often when you change the technological stack, some new functionality is always needed as well.
We had to add new data module processing to Pipeline to support functionality that was not yet in production.
This task means we have new data sources and new business transformation rules, and need to update the Data Mart structure to receive the resulting data. It required changes, which means testing of all Pipeline components… including data sources.
Test Data Source

In this area, risks are often underestimated:
- some specialists consider it a “foreign zone of responsibility”;
- they take it as an axiom that the data in the source has already passed a set of checks and cannot be erroneous;
- or it often happens that there is no real data (e.g. the functionality saving the data to the source is not ready or an “upstream” ETL is not built), and the testers need to recreate the test data from scratch.
So, how did we cope and find all gaps between the described requirements and expectations?
1) These are questions for an Expert – how the data gets into the system and whether it’s possible to modify it over time, and just how exactly. Sometimes during such conversations, rethinking comes to our minds, and the source design or ETL requirements change.
2) Search for any tech possibility of non-compliance with the data source and the requirements.
Most of the problems that we met were caused by manual edits of data sources, happened by-passing the standard data flow. And due to the wrong design of the tables, the “human factor” appeared, and there was data duplication or a breakdown in the relationships between them.
Why bother spending time and double-checking? Because a user will see all defects through the BI application and a bug will be escalated to you, detracting from other important things, and only then you will redirect it to guys responsible for the source data. Earlier issue detection makes the feedback loop much shorter.
Therefore, if we found an issue but did not have the opportunity to change the source, we documented the risks and introduced them to Product Owner and Production Support Group, and included Exceptions processing into the ETL logic (for example, if the data was accidentally duplicated due to the lack of the correct key, we can use the record that was added later).
Test Target Data Model

During the checking we:
1) verified that “common decency rules” are followed and the same entities and attributes are called identically in different tables (if even one letter is different, you will hate it when writing queries, and if it makes it to production, it will be difficult and expensive to change it later on).
2) verified that the new structure was optimal for building reports and graphs, i.e. possible preaggregation, denormalization, etc. were introduced. For example, the metric is set up as a field in the database, rather than at the visualization level for faster chart loading, or, if necessary, the data in a table is multiplied by parameters for faster filtration.
3) check, where applicable, if the table contains fields that facilitate verification of complex calculations (you can always ask to add those) as well and logging fields (the date when the record was saved).
Functional ETL Testing
Data Quality tests
We started checking the accuracy of the data processing with quick and straightforward tests localized to the Target Data Mart.

At first, we wrote a Smoke suite, and next we created Data Quality tests that check Target Data Mart for compliance with the requirements, including all sorts of implicitly designated logical restrictions.
For automation, we used the Fitnesse framework and one of the DBLib features — “Query”. The parameter of which is a query and an expected result can be set up as 0 records.
For example, for the initial check of the patient age with the absence of the date of birth field, you can see that there are no data with zeros, negative values, and there are no people with the age of more than 125 years.
Such simple tests can identify many ETL process errors without the need to compare data from the source with the target Data Mart.
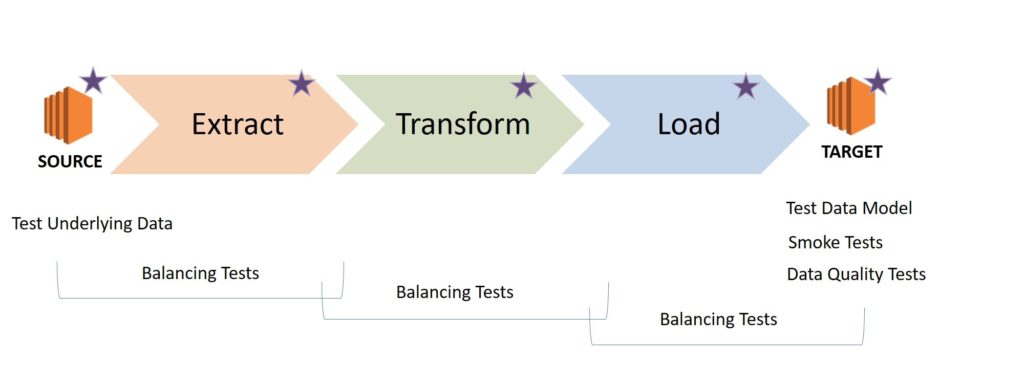
Balancing Tests

Finally, we wrote Balancing Tests that simulate the ETL process to see that all data from the sources was correctly reflected in Data Mart, and there is nothing extra in it.
These tests are implemented using the so-called Minus queries, where the results of the two subqueries are compared.
The first is a request to data sources that mimics business requirements, and the second is a request to Data Mart.
To write such tests, you need to clearly understand how the data in the source and Data Mart are related (1: M, N: 1, M: N), how the entities correspond to each other, what types of transformations are applied to the data and whether all the data in Data Mart is updated or not.
Requests that we wrote must be checked for their ability to detect errors. You can do it through intentionally corrupting data in Data Mart (e.g. add or delete records, etc.) and check that a mistake has been found. Actually, this rule applies to all tests – checks must be checked.
Finally, each Balancing test must be bilateral. You check that all the right data from source made it to the target and that all data in the target is the right one.
Balancing Tests challenges
It may be difficult to create such tests because all the data is on different servers in different systems, and it’s impossible to access them in one request.
It was no longer the case for us, as we gathered it all in one place – Data Lake – data from all sources as well as the results of the transformation. These are files in Amazon S3 that can be used for tables creation via Amazon Athena, an interactive query service, or data catalog set up via Amazon Glue. Thus we can reach them in one request and write Minus queries. And of course, keep test suites in FitNesse for convenience.
Most Common bugs
- Count Mismatch (including Duplicates);
- Anomalies issues: Null or Length relevant;
- Date relevant calculations.
Which bugs found by Minus queries are most common?
Often data is lost, or there is erroneous extra one in the target, e.g. duplicates due to improperly applied conditions of joins or filtering.
NULL values are not processed correctly. For example, they are replaced by an empty string or are not taken into account in the transformation condition.
We also should be attentive regarding the dates, especially when it comes to various Time Zones (whether unification is necessary or not), and non-standard fiscal periods (if the formula uses the current date, you need to check whether this formula will work correctly in the first and last month of the year).
ETL Testing Challenges
What other difficulties may arise?
Even the simplest queries in Athena can “freeze” when Amazon did not have enough resources (for such requests, resources are allocated according to the residual principle).
Some of the transformations were quite complex, and the creation of an exhaustive test set is equal to ETL creation.
Also, sometimes, it’s impossible to verify the entire data set due to the large amount of it.
To solve this, we needed to apply the methods mentioned earlier:
1) Start with the easiest tests and then move on to the heavy ones. At first, we compare the number of records, the minimum, maximum, average values in the field, checksums, and finally, the content.
2) Limit the data. For example, look at one period. In other words, we take data for a year or data of just one client.
3) Simulate a test set.
Visualization in Data QA
You can use visualization with the products that are already used on the project to analyze and model test data, and draw up the correct set of checks – for example, Tableau.
Also, you can compare the results of two different ETLs if they work with the same data (we had Elastic Kibana).
The last product we used was Apache Zeppeling, which helped to create a cluster for running tests, thereby solving the Athena resource limitation problem and allowed us to use standard visualizations.
Ongoing Support
The task of monitoring the Pipeline operation in production was transferred to Production Support Group. The testers made sure that alerts are set up for critical events, and processes to respond to the Pipeline Fall or delay were defined.
In addition, Pipeline was incorporated into a Data Integrity project, which collects checksums and uses New Relic for log analysis.
Finish
ETL testing, like other types, is the one where you need to check the result of the system against the set up requirements.
There is no graphical interface with intuitive functions, and the tester should be well versed in data and be able to write queries.
However, if you know the right approaches and have a basic understanding of Amazon services, you can choose the right strategy.
And in conclusion.
What is the difference between ETL testing and data warehouse testing?
Pipeline quality assurance practices described above and those listed in the first article (Data Pipeline Installation Quality) are of course still just a part of data warehouse testing, which goes beyond that.
When you build a system from scratch, as you also need to verify a data management product by doing performance, stress and recovery testing for it and make sure that front-end applications marry it nicely and of course address security.
WANT TO KNOW HOW TO BUILD SCALABLE PRODUCT?
When developing a product, we follow these four critical rules to deliver high qualitydata development services.





